网易数帆黄久远:大规模Kubernetes监控体系建设之路
本文由本人整理,发表在CSDN平台并署名【小雨青年】。
嘉宾 | 黄久远 整理 | 小雨青年
出品 | CSDN云原生
2022年5月31日,在CSDN云原生系列在线峰会第6期“K8s大规模应用和深度实践峰会”上,网易数帆技术专家黄久远从系统性风险的产生及监控体系的打造等方面,分享了大规模Kubernetes监控体系建设目标的实现。
一、系统性风险的产生
Kubernetes在网易的规模化落地大致经历了三个阶段:
2018年,业务容器化的初期:集群数量在二十个左右,处于较低水平。应用和云原生技术的融合程度较低,定制化方案和咨询的需求较多。
2020年,业务大规模容器化落地:集群数量较多,部分业务逐渐了解Kubernetes技术,通用需求开始涌现。
2021年,内部大部分业务基本完成落地:集群数量超过 100 个,部分业务基于云原生技术打造业务平台,变更和发布常态化。
在Kubernetes引入的早期,网易使用Prometheus作为集群监控的解决方案。
下图为Prometheus官网提供的架构图,这从侧面表明了Prometheus本身运维的复杂性。例如,官方没有提供用于变更Target、Rule等常用配置的HTTP接口。
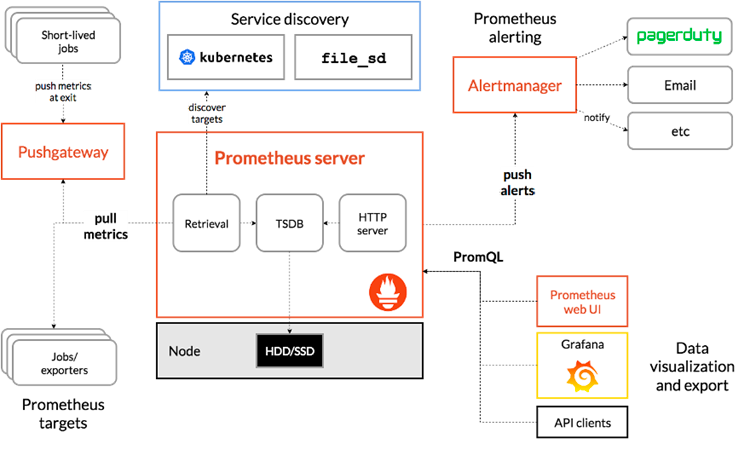
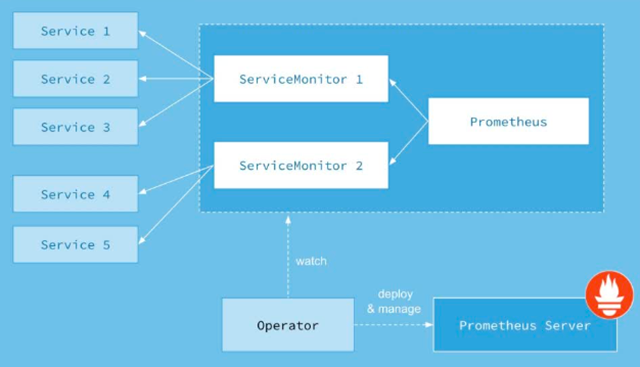
为了解决Prometheus运维复杂性的问题,网易引入了Prometheus Operator,用于管理集群中的Prometheus实例。它通过Kubernetes为Prometheus的运维管理提供接口,Target、Rule等配置的变更可以通过ServiceMonitor、PrometheusRule等自定义资源进行管理。
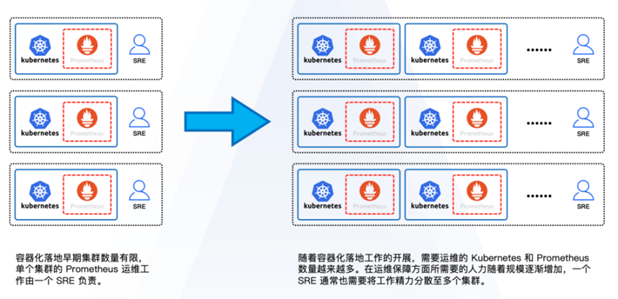
经过业务的发展,这种烟囱式的解决方案已经不能满足需求。从开始的一个SRE负责两三个集群,到后来负责多个集群,精力分散导致服务质量下降。
越来越多的业务用户开始自定义Prometheus Target和Prometheus Rule,并且通过Grafana Dashboard来管理监控视图。早期烟囱式的发展模式逐渐难以支撑更加复杂的规模化场景,于是网易发展出了标准化的API,通过平台托管用户需求。
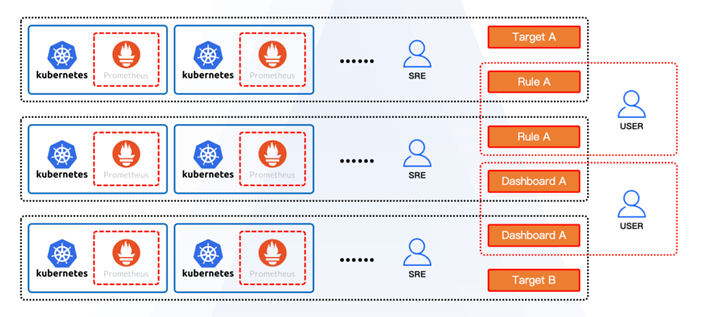
随着用户对于Kubernetes更加深入的了解,同时SRE的工作和用户有一部分重合,网易开始产生了一些平台化的思考,去定义清晰的边界,让大家各司其职。
二、平台化的思考
首先来了解一下什么是平台化。平台化的必要条件是标准化:
Kubernetes提供管理资源的API标准;
Prometheus提供监控指标的管理标准;
Grafana提供监控可视化的标准;
Prometheus Operator提供在Kubernetes集群中管理Prometheus规则的API标准。
容器技术为应用的管理提供了封装标准和平台化的基础,开发人员将容器镜像上传到Harbor这样的平台,运维人员通过Harbor获取镜像进行应用交付。
Prometheus Operator等方案基于Kubernetes的声明式API为监控资源的管理提供了封装标准和平台化的基础,可以打造监控平台进行标准化的交付件管理,以实现运维人员和研发人员边界清晰,使其各司其职,高效地迭代业务。
多个用户在基础组件的监控上往往有着相同的需求,SRE通常在这些用户的集群中交付相同的ServiceMonitor、PrometheusRule、GrafanaDashboard等资源。
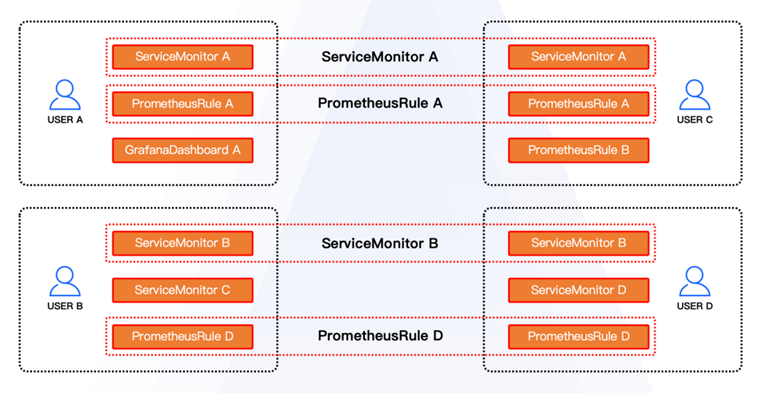
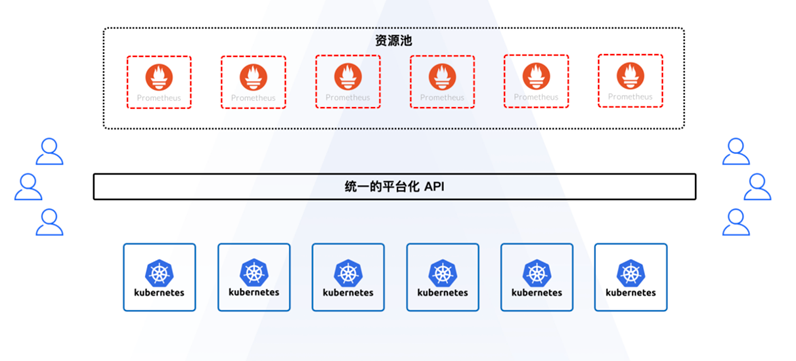
有的用户存在一些存量资源没有使用Kubernetes,但使用了Prometheus的情况。当他们希望使用云原生技术去管理这些存量业务时,平台就可以用资源池的形态对Prometheus、Grafana等组件进行运维管理,通过统一的平台化API为用户提供相关的SaaS或者PaaS服务。
三、监控体系的打造
基于平台化的思考,网易数帆开始着手打造监控体系。大致分为以下几步:
推标准——推广并落地统一的云原生体系监控标准;
提效率——平台化封装,提升监控方案的管理和交付效率;
降成本——降低Prometheus等基础组件的资源成本;
谋发展——提升云原生体系下运维诊断的自动化程度。
以Cortex为例,传统的Prometheus Operator的烟囱式方案对资源的利用率较低,成本压力会随着集群数量增长。但Cortex能够提供指标存储的集团全局视图,很好地解决了大规模场景下资源管理和指标查询问题。
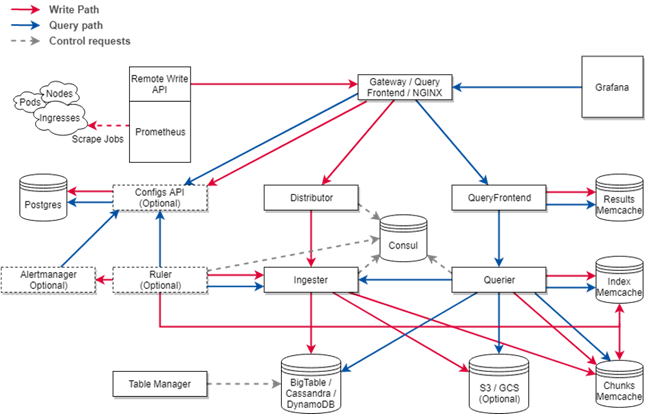
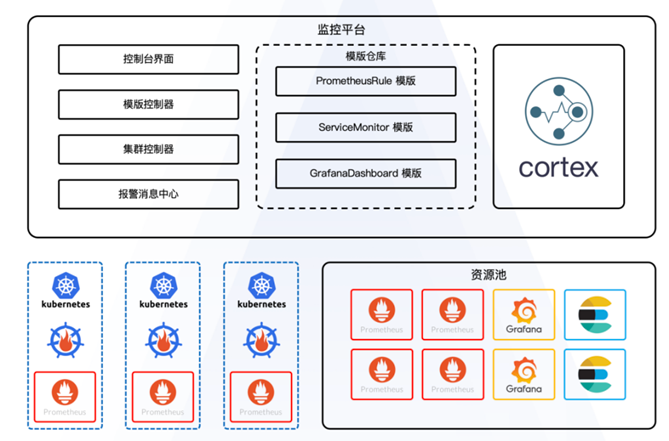
整个监控体系主要包括以下组件:
控制台界面,标准化的API为用户提供清晰的接入层;
模板控制器,通过模板仓库,将PrometheusRule、ServiceMonitor、GrafanaDashboard的模板下发到各个集群中;
集群控制器,控制了每个集群对应的路由信息;
报警集群中心,接收所有集群的报警消息;
资源池,托管了 Prometheus 、Grafana 、Elasticsearch组件;
中心化管理,每个集群通过Prometheus Operator做集群内的报警规则交付件的管理。
那么,单个集群是如何做的呢?
如下图所示,Prometheus通过配置Remote Read和Remote Write参数接入Cortex,做到了从烟囱式的管理到统一化的管理。
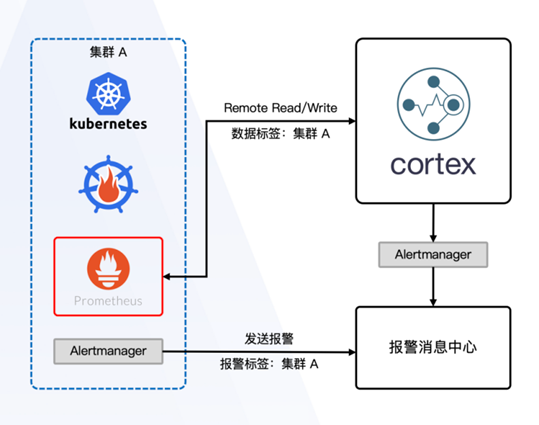
Prometheus写入Cortex的数据包含集群标签。Alertmanager将报警发送至报警消息中心进行统一管理。Alertmanager发送的报警包含集群标签,对于现有用户来说,实现成本极低。
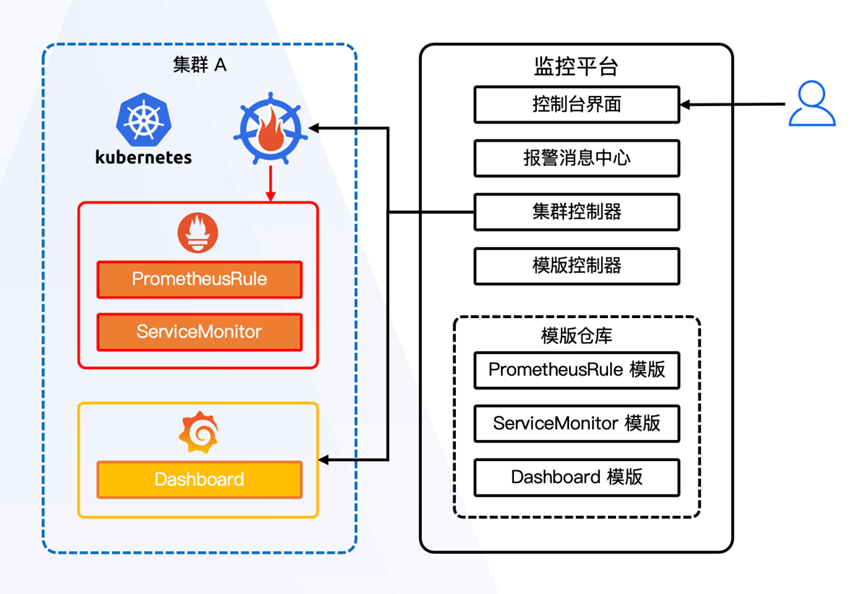
通过对单集群的管理,进而实现了统一标准化管理:
用户通过控制台界面管理集群中的监控资源;
集群控制器与每个集群中的Prometheus Operator和Grafana建立联系;
模版控制器管理用户提交至模版仓库中的交付件以及版本。
正在规划中的资源池管理,内部部署大量Prometheus、Grafana实例,对外提供PaaS级别的监控服务。
用户可以通过平台访问Prometheus和Grafana托管服务,通过资源池对Prometheus和Grafana服务进行中心化管理。访问路由可以将Prometheus和Grafana页面代理到平台的控制台界面。

下面举两个经典的业务支撑场景的例子。
场景一:用户部署资源属于用户自己的资产,平台提供方案和咨询服务。
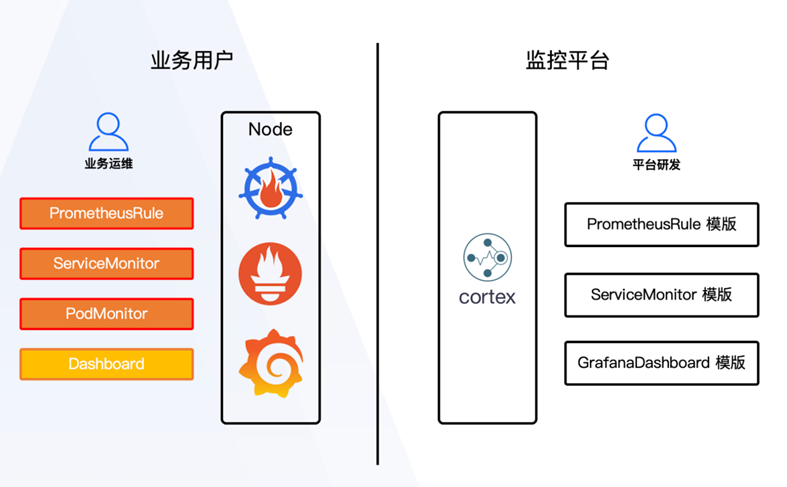
用户在集群中提供用于部署Prometheus和Grafana的计算资源。
用户委托平台对集群内Prometheus和Grafana的规则配置进行管理。
用户通过平台查看对应集群的Prometheus和Grafana页面。
场景二:偏全托管的形式,用户不提供Prometheus资源,而是使用中性化的PaaS服务。

用户使用中心化托管的Prometheus和Grafana服务。
用户通过平台自行管理Prometheus和Grafana的规则配置。
四、精细化管理
在平台化的目标达成后,下一步则是实现更加精细化、更高自动化。
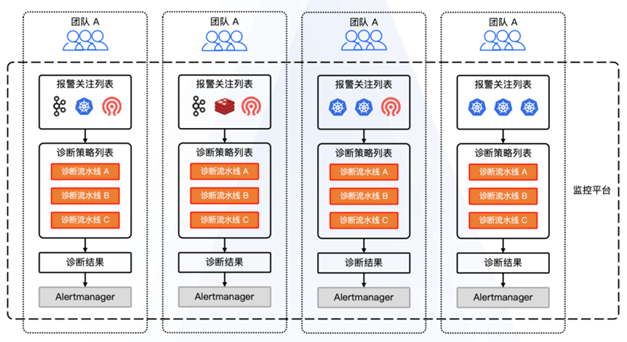
平台化完成之后,便接入了大量内部业务,此时消息的复杂程度会呈现爆炸式增长。
多个集群下,一条报警消息需要多个集群按不同重要程度去接收,这就需要自动报警诊断的能力去实现。
五、价值收益
上述监控体系的建设,为公司创造了很大的价值。
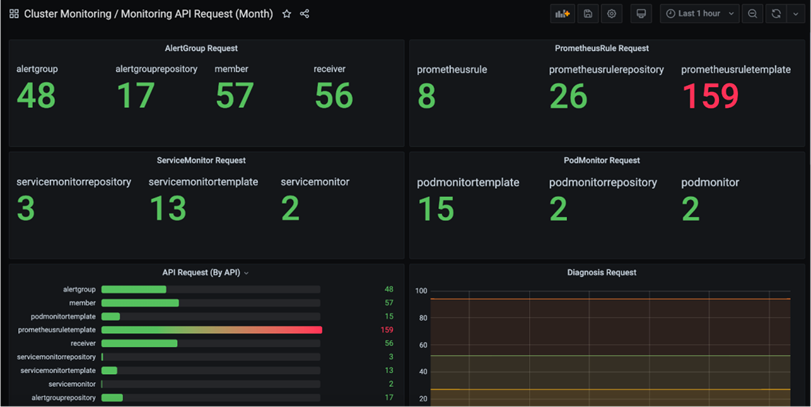
第一,公司层面的全局视图。
直观显示审计用户调用平台的次数,对工作有整体的认识。
第二,每个阶段对应的价值收益。
在每个阶段,考虑的事情和技术选型有一定的差异性,但路线串起来之后又具有连续性。
2018年,Prometheus Operator较好满足了容器化初期的需求;运维部署简单;规则和服务发现项维护成本较低。
2020年,Cortex解决了大规模场景下的资源管理问题;监控平台为通用需求提供了快速交付的模版;打破多个团队之间监控数据的孤岛;模版标准化交付使团队的工作以及价值产生连续性。
2021年,Prometheus资源池化进一步压缩了资源成本;KubeDiag项目的全面落地进一步提升了监控报警的自动化处理能力和效率。
以上是对大规模Kubernetes监控体系建设的简单分享,希望对大家有所帮助。